
Contenus
- Introduction
- XML et TEI : vers un standard de l’encodage de textes
- Structure minimale d’un document TEI
- Conclusion
- Références recommandées
Note de la traductrice :
Dans la leçon originale, Nicolás Vaughan utilise des exemples tirés du Quichotte de Miguel de Cervantes, ainsi que les quatre premiers vers du sonnet « Amor constante más allá de la muerte » (« Amour constant au-delà de la mort ») de Francisco de Quevedo. Afin de mieux adapter la traduction à un lectorat francophone, lui proposant des textes originellement écrits en langue française, j’ai choisi de remplacer :
-
L’extrait du Quichotte par un extrait des Misérables de Victor Hugo,
dans les exemples comprenant des petites capitales et la balise
<name>; -
Les informations qui correspondent aux métadonnées de l’édition du Quichotte par des
informations sur les métadonnées de l’édition des Misérables, lors de l’explication
de l’élément
<teiHeader>; - Les quatre premiers vers du sonnet de Quevedo par les quatre premiers vers du « Sonnet VIII » de Louise Labé, lors de l’explication de l’encodage de textes en vers.
Introduction
Dans les humanités numériques, l’un des problèmes centraux consiste à travailler avec et sur les textes : leur capture (numérisation), reconnaissance, transcription, encodage, traitement, transformation et analyse. Dans cette leçon, nous nous concentrerons exclusivement sur l’encodage du texte, c’est-à-dire, sur sa structuration sémantique ou formelle au moyen de balises (tags).
Un exemple peut éclairer cette idée. Supposons que nous avons un document imprimé que nous avons préalablement numérisé. Nous avons les images numérisées des pages et, à l’aide d’un logiciel de reconnaissance optique de caractères (OCR, en anglais), nous extrayions le texte contenu dans ces images. Ce texte est ce que l’on appelle habituellement texte brut (ou texte numérisé), c’est-à-dire, le texte sans aucun format (sans italiques, gras, etc.) ni aucune autre structuration sémantique.
Même si cela peut paraître étrange, le texte brut est complètement dépourvu de contenu. Pour un ordinateur, ce n’est qu’une longue chaîne de caractères (y compris la ponctuation, les espaces, les sauts de ligne, etc.) dans un encodage (par exemple UTF-8 ou ASCII) d’un alphabet (latin, grec ou cyrillique, par exemple). C’est nous qui, lorsque nous le lisons, identifions des mots (dans une ou plusieurs langues), des lignes, des paragraphes, etc. C’est nous qui identifions aussi les noms de personnes et de lieux, les titres d’ouvrages et d’articles, les dates, les citations, les épigraphes, les références croisées (internes et externes), les notes en bas de page et les notes à la fin du texte. Mais, de nouveau, l’ordinateur est complètement « ignorant » à l’égard desdites structures textuelles dans un texte brut sans traitement ou encodage.
Sans encodage TEI (Text Encoding Initiative) réalisé par un être humain, l’ordinateur ne peut identifier aucun contenu sémantique dans le texte brut. Cela veut dire, entre autres choses, que nous ne pouvons pas faire des recherches structurées sur ce texte (de noms de personnes, de lieux ou de dates, par exemple), et que nous ne pouvons ni extraire ni traiter systématiquement une information, sans avoir préalablement indiqué à l’ordinateur quelles chaînes de caractères correspondent à quelles structures sémantiques. Par exemple, cette chaîne de caractères correspond à un nom propre de personne, cet autre nom de personne fait référence à la même personne que le premier, cette chaîne de caractères est un nom de lieu, cette autre est une note en marge faite par une tierce personne, ce paragraphe appartient à cette section du texte. Encoder le texte, c’est indiquer (au moyen de balises) que certaines chaînes de caractères en texte brut ont une signification donnée. Il s’agit ici de la différence principale entre le texte brut et le texte sémantiquement structuré.
On peut encoder un texte de différentes façons. Par exemple, nous pouvons mettre entre astérisques uniques les noms de personnes : *Simón Bolívar*, *Soledad Acosta*, etc. Et entre astérisques doubles ceux de lieux : **Bogotá**, *Firmingham*, etc. Nous pouvons aussi utiliser des tirets bas pour indiquer les noms d’œuvres : _La Divine comédie_, _Cent ans de solitude_, etc. Ces signes servent à baliser ou marquer le texte qu’ils contiennent, afin d’identifier dans le texte un contenu donné. Comme on peut l’imaginer, les possibilités d’encodage sont presque infinies.
Dans cette leçon, vous apprendrez à encoder des textes en utilisant un langage de balisage spécialement conçu pour cela : la TEI (Text Encoding Initiative).
Le logiciel que nous utiliserons
N’importe quel éditeur de texte capable de produire du texte brut (format .txt) nous servira pour cette leçon : le Bloc-notes (Notepad) de Windows, par exemple, est parfaitement approprié pour cela. Néanmoins, il y a d’autres éditeurs de texte qui offrent des outils ou des fonctionnalités conçus pour faciliter le travail avec du XML (Extensible Markup Language), voire avec de la TEI. Oxygen XML Editor est l’un des plus recommandés actuellement, disponible pour Windows, macOS et Linux. Néanmoins, ce n’est pas un logiciel gratuit (la licence académique coûte environ 84€) ni à code source ouvert, par conséquent nous ne l’utiliserons pas dans cette leçon.
Pour cette leçon, nous utiliserons l’éditeur Visual Studio Code (VS Code, plus brièvement), créé par Microsoft et entretenu actuellement par une grande communauté de programmeurs et programmeuses de logiciels libres. C’est une application complètement gratuite et à code source ouvert, disponible pour Windows, macOS et Linux.
Téléchargez la version la plus récente de VS Code sur le lien https://code.visualstudio.com/ et installez-la sur votre ordinateur. Ouvrez-le et il affichera l’écran suivant :
Figure 1. Vue initiale de VS Code.
L’éditeur de code proposé lors de cette leçon est Visual Studio Code (VS Code), un logiciel libre créé par Microsoft, mais qui inclut de la télémétrie par défaut et dont certaines extensions ne sont pas libres. Il nous semble donc important de mentionner une alternative, VSCodium, proposée par une communauté open source. À la différence de VS Code, VSCodium n'active pas la télémétrie par défaut, ne met à disposition que des extensions non propriétaires et offre systématiquement une licence MIT de réutilisation.
Maintenant, nous allons installer une extension de VS Code pour travailler plus facilement avec des documents XML et XML-TEI : Scholarly XML.
Pour ce faire, cliquez sur le bouton Extensions dans la barre latérale sur le côté gauche de la fenêtre principale :
Figure 2. Extensions de VS Code.
Écrivez Scholarly XML sur la barre de recherche :
Figure 3. Recherche d’une extension sur VS Code.
Enfin, cliquez sur Install :
Figure 4. Installer Scholarly XML sur VS Code.
Cette extension nous permet de faire plusieurs choses avec le code :
Premièrement, Scholarly XML permet de sélectionner n’importe quel texte dans un document XML, d’utiliser des raccourcis clavier et d’inclure automatiquement le texte sélectionné à l’intérieur d’un élément XML. Lorsque nous appuyons sur Ctrl+E (sur Windows ou Linux) ou Cmd+E (sur macOS), VS Code ouvre une petite fenêtre avec l’instruction Enter Abbreviation (Press Enter to confirm or Escape to cancel) — « Introduisez le raccourci (Appuyez sur ‘Entrée’ pour confirmer votre saisie, ou sur ‘Échap’ pour l’annuler) ». Ensuite, nous écrivons le nom de l’élément et appuyons sur la touche Entrée. Ainsi, l’éditeur intégrera le texte sélectionné entre une balise d’ouverture et une autre de fermeture avec le nom de l’élément. Lorsque nous travaillons avec XML, automatiser l’introduction de balises d’ouverture et de fermeture peut nous faire économiser beaucoup de temps, tout en diminuant la probabilité d’introduire des erreurs typographiques dans le code.
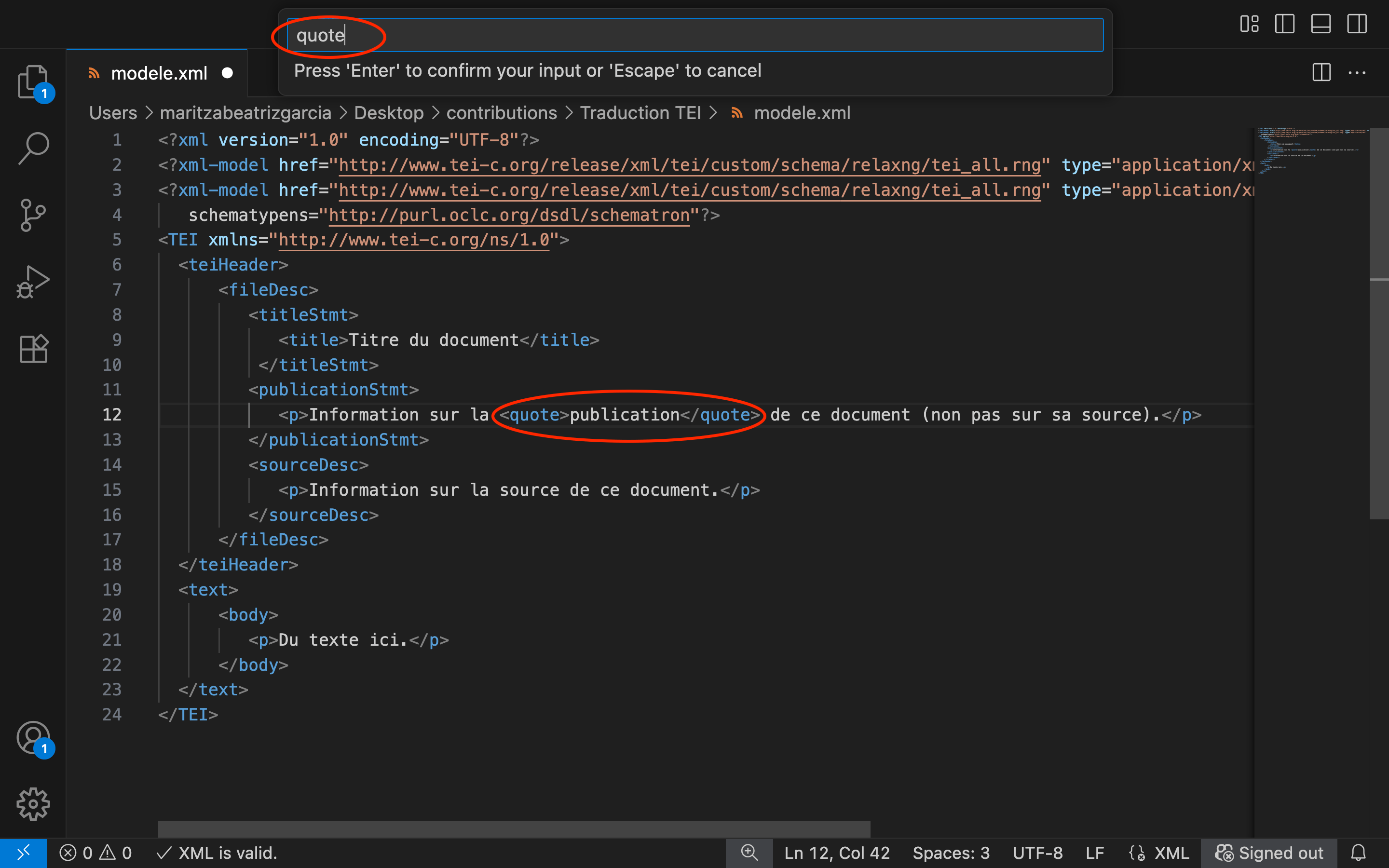
Figure 5. Introduire automatiquement un élément XML sur VS Code.
Deuxièmement, Scholarly XML permet de déterminer si un document est bien formé selon la syntaxe XML et, en outre, s’il est valide par rapport à un schéma de validation de type RELAX NG, par exemple, le schéma tei-all de la TEI, qui contient la totalité des modules de marquage pour tous les types de documents prévus par le consortium de la TEI. (Nous expliquerons plus bas les concepts de conformité et validité, à la fois syntaxique et sémantique.) L’extension réalise automatiquement les deux choses.
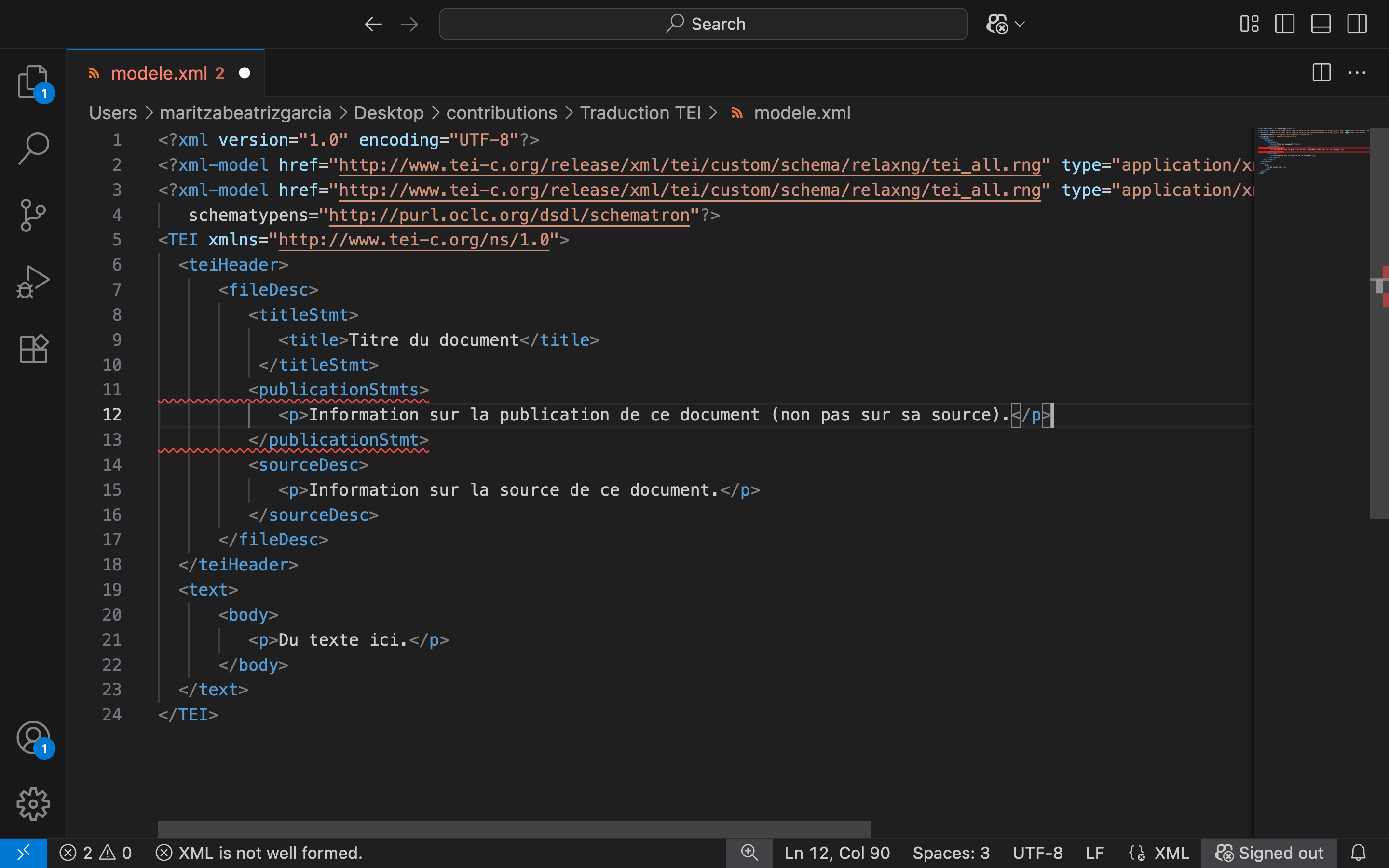
Figure 6. Détecter des erreurs XML sur VS Code. En raison d’une erreur dans le nom de la balise ouvrante ‘publicationStmts’, celle-ci et la balise fermante ‘publicationStmt’ sont soulignées en rouge.
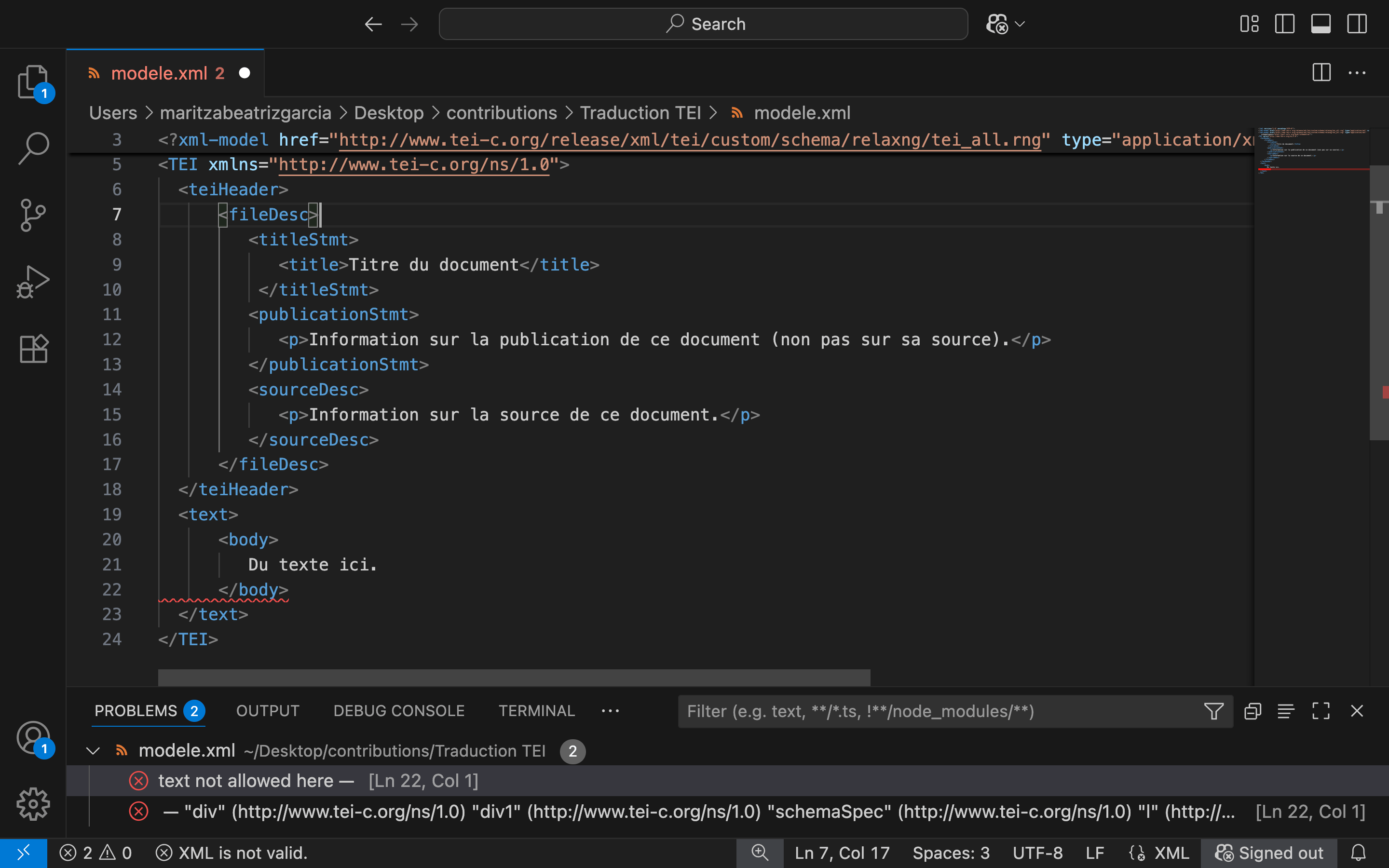
Figure 7. Détecter des erreurs XML sur VS Code
Cependant, pour réaliser le deuxième type de validation, il est nécessaire de spécifier l’URI du schéma dans une déclaration <?xml-model> au début du document, par exemple, ainsi :
<?xml-model href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng" type="application/xml" schematypens="http://relaxng.org/ns/structure/1.0"?>
<?xml-model href="http://www.tei-c.org/release/xml/tei/custom/schema/relaxng/tei_all.rng" type="application/xml"
schematypens="http://purl.oclc.org/dsdl/schematron"?>
Vous pouvez télécharger un modèle basique de document XML-TEI depuis le dépôt Programming Historian, avec ces lignes déjà incluses : cliquez droit sur le lien, puis sélectionnez Enregistrer la cible du lien sous (ou Enregistrer sous) pour le sauvegarder sur votre ordinateur.
Troisièmement, l’extension offre également des outils d’autocomplétion du code XML à partir du schéma de validation RELAX NG. Par exemple, si nous introduisons dans le document un élément <q> : « quoted » (pour marquer un texte entre guillemets, par exemple une citation), nous pouvons appuyer sur la barre d’espace après le q de la balise d’ouverture et VS Code affichera une liste d’attributs possibles à sélectionner dans le menu :
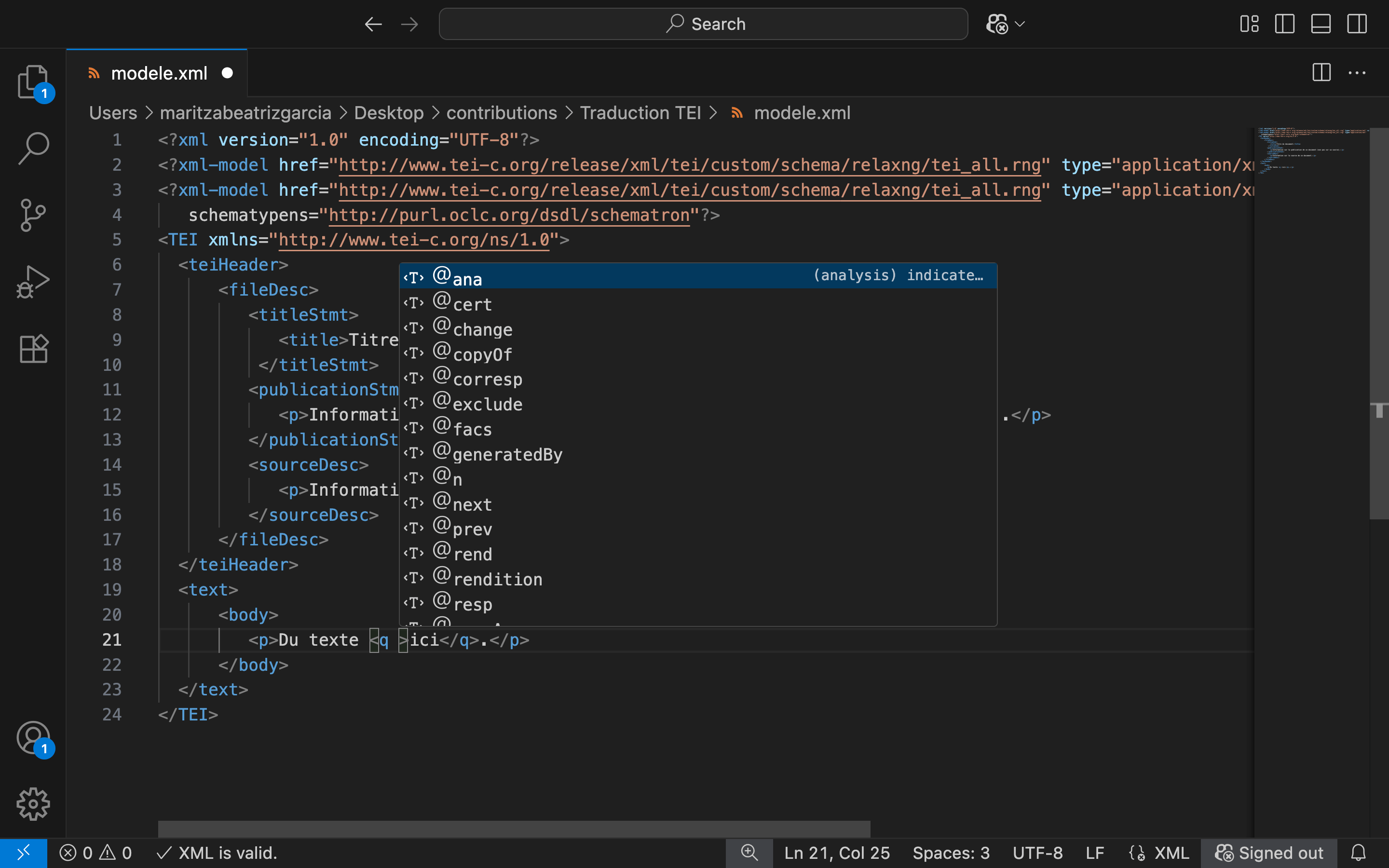
Figure 8. Menu d’autocomplétion de code XML sur VS Code.
Cependant, pour pouvoir utiliser cette extension ou d’autres dans VS Code, il est nécessaire que l’éditeur ne soit pas en mode restreint (Restricted Mode), comme ce qui s’affiche sur cette fenêtre :
Figure 9. Avertissement du mode restreint sur VS Code.
Ce mode empêche les extensions ou le code du document d’exécuter des instructions qui pourraient endommager votre système ou vos fichiers. Étant donné que nous sommes en train de travailler avec nos documents et que l’extension recommandée est hautement fiable, nous pouvons désactiver le mode restreint en cliquant sur l’hyperlien situé en haut, qui indique Manage (« Administrer ») et puis cliquer sur le bouton Trust (« Faire confiance »), ainsi :
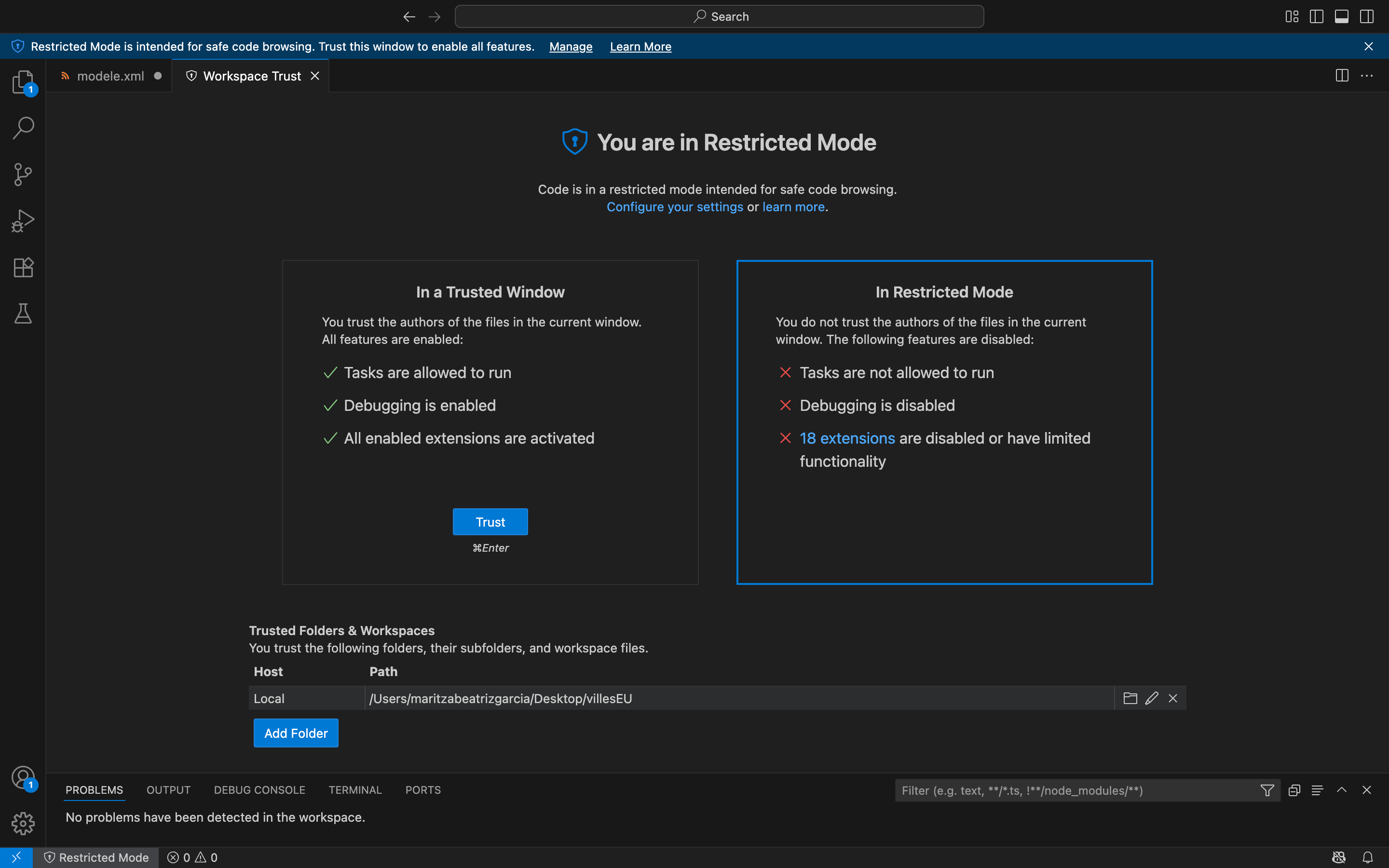
Figure 10. Quitter le mode restreint sur VS Code.
Maintenant que nous avons configuré notre éditeur, nous pouvons commencer à travailler en XML-TEI.
Visualisation ou description sémantique
Les personnes familiarisées avec le langage de marquage Markdown – de nos jours habituel dans des forums techniques sur Internet, ainsi que dans GitHub, GitLab et d’autres répertoires de code – reconnaîtront certainement l’usage d’éléments tels que des astérisques (*), des tirets bas (_) et des dièses (#) pour faire en sorte que le texte apparaisse d’une certaine manière dans le navigateur. Par exemple, un texte placé entre deux astérisques simples sera montré en italique, tandis qu’un autre entre astérisques doubles le sera en gras. De fait, le texte de cette leçon est écrit en Markdown et suit ces conventions.
Cet usage du marquage a pour finalité principale la visualisation du texte, non pas sa structuration sémantique. Autrement dit, les balises de Markdown ne fournissent aucune indication sémantique sur le texte balisé (par exemple, s’il s’agit du nom d’une personne, d’un lieu ou d’une œuvre), mais indiquent seulement comment cet extrait doit être visualisé ou restitué dans un navigateur ou un autre médium.
Comprendre la différence entre le marquage de visualisation (Markdown) et le marquage structurel et sémantique (TEI) est crucial. Contrairement au Markdown, la TEI permet d’encoder aussi bien le sens que la forme d’un texte. Le choix des éléments à encoder dépend des objectifs du projet : identification sémantique (noms de personnes, lieux, œuvres), structure matérielle (mise en page, organisation physique), ou les deux. La personne qui effectue l’encodage n’est donc pas tenue de reproduire la forme du texte source : elle choisit de l’encoder ou non selon la pertinence de cette information pour son projet.
Clarifions cela en revenant à notre exemple initial. Supposons que, dans le texte numérisé de départ, les noms propres apparaissent toujours imprimés en petites capitales, comme dans le fragment qui suit :

Figure 11. Court extrait de texte numérisé tiré des Misérables.
Comme nous le verrons, la TEI nous permet d’encoder, par le moyen d’une série de balises, le texte que nous voulons structurer sémantiquement. Par exemple, nous pouvons utiliser une balise comme <name> pour démarquer les noms propres contenus dans le texte, ainsi :
Quand <name>Zoïle</name> insulte <name>Homère</name>, quand <name>Mævius</name> insulte <name>Virgile</name>, quand <name>Visé</name> insulte <name>Molière</name>,
quand <name>Pope</name> insulte <name>Shakespeare</name>, quand <name>Fréron</name> insulte <name>Voltaire</name>, c’est une vieille loi d’envie
et de haine qui s’exécute ; les génies attirent l’injure, les grands hommes sont toujours plus ou
moins aboyés.
Nous verrons en détail ce qu’est et comment fonctionne une balise (ou plus précisément un élément) en XML et TEI. Pour le moment, remarquons qu’une balise <name> ne signifie pas que le texte ait été représenté originellement en petites capitales (ni d’une autre manière). Cela signifie seulement que le texte qu’elle contient est un nom propre, indépendamment de la manière dont il est représenté. De fait, nous pouvons encoder exhaustivement un document avec des centaines ou des milliers de balises, sans que cet encodage ne se traduise visuellement dans une éventuelle représentation finale.
XML et TEI : vers un standard de l’encodage de textes
Depuis les débuts des humanités numériques, dans les années 1960, de nombreuses méthodes d’encodage de textes ont été proposées. Presque chaque projet d’encodage contenait son propre standard, ce qui conduisait au fait que les projets étaient incompatibles et intraduisibles entre eux, entravant, voire rendant impossible, le travail collaboratif.
Pour résoudre ce problème, une vingtaine d’années plus tard, on a établi un nouveau standard d’encodage de textes, rassemblant un grand nombre de chercheurs et chercheuses à travers le monde, particulièrement dans les universités anglosaxonnes : la Text Encoding Initiative (TEI).
La TEI est également construite sur le langage de marquage XML, c’est pourquoi elle est parfois dénommée comme « XML-TEI » (ou encore « TEI-XML »). De son côté, le XML (le sigle d’« eXtensible Markup Language ») est un langage d’ordinateur dont le propos est de décrire, par le moyen d’une série de marques ou de balises (tags en anglais), un objet-texte donné.
Le XML et la TEI sont des langages de marquage et c’est en cela qu’ils se différencient des langages de programmation comme C, Python ou Java, qui décrivent des objets, des fonctions ou des procédures qui doivent être exécutés par un ordinateur.
XML
Dans cette leçon, nous n’entrerons pas dans le détail de la syntaxe ni du fonctionnement de XML. Nous recommandons donc que le lecteur ou la lectrice jette un coup d’œil à la leçon de M. H. Beals « Transforming Data for Reuse and Re-publication with XML and XSL » (en anglais) pour plus d’information sur le XML, ainsi qu’à la bibliographie et aux références suggérées à la fin de cette leçon.
Pour le moment, nous devons seulement savoir que tout document XML doit respecter deux règles essentielles pour être valable :
- Il ne doit y avoir qu’un seul élément racine (qui contient tous les autres éléments, s’il y en a d’autres).
- Toute balise d’ouverture doit avoir une balise de fermeture.
Heureusement, les éditeurs de code XML comme VS Code (avec l’extension Scholarly XML) ou OxygenXML nous permettent de détecter facilement des erreurs de ce type.
Qu’est-ce que la TEI ?
Le XML est un langage si général et abstrait qu’il est indépendant vis-à-vis du contenu. Il peut être utilisé, par exemple, pour décrire des choses très différentes, allant d’un texte en grec classique du VIIIe siècle av. notre ère à un message qu’un thermostat intelligent envoie à une application de smartphone utilisée pour le contrôler.
La TEI est une implémentation particulière de XML, c’est-à-dire une série de règles qui déterminent quels éléments et quels attributs sont permis dans un document en fonction de sa typologie. Cet encodage permet le traitement informatique de ces textes, qui peuvent alors être analysés, transformés, reproduits et stockés, selon les besoins des usagers et usagères. La TEI occupe une place centrale dans les humanités numériques, car elle permet de manipuler informatiquement les textes, objets d’analyse au cœur des humanités. Contrairement au XML, qui permet d’encoder tout type d’information, la TEI est spécifiquement conçue pour encoder des textes et leurs propriétés.
Les types d’éléments et d’attributs autorisés en TEI, et les relations existantes entre eux, sont spécifiés par les règles de la TEI. Par exemple, si nous voulons encoder un poème, nous pouvons utiliser l’élément <lg> (de line group, « groupe de lignes ») de la TEI. Les règles de la TEI déterminent quels types d’attributs peut avoir cet élément et quels éléments peuvent, eux-mêmes, le contenir ou être contenus par lui. La TEI détermine que tout élément <lg> doit avoir au moins un élément <l> (de verse line, « vers »).
Pour illustrer nos propos, examinons les quatre premiers vers du Sonnet VIII de Louise Labé (ci-dessous, en texte brut) :
Je vis, je meurs : je me brûle et me noie,
J’ai chaud extrême en endurant froidure ;
La vie m’est et trop molle et trop dure,
J’ai grands ennuis entremêlés de joie.
Nous pouvons proposer l’encodage en TEI qui suit :
<lg met="10,10,10,10" rhyme="abba">
<l n="1">Je vis, je meurs : je me brûle et me noie,</l>
<l n="2">J’ai chaud extrême en endurant froidure ;</l>
<l n="3">La vie m’est et trop molle et trop dure,</l>
<l n="4">J’ai grands ennuis entremêlés de joie.</l>
</lg>
Dans le cas présent, nous avons fait appel à l’attribut @rhyme de l’élément <lg>, pour faire encoder le type de rime du passage ; à l’attribut @met pour indiquer le type de métrique du premier vers – décasyllabe – ; et finalement à l’attribut @n pour indiquer le numéro du vers à l’intérieur de chaque groupe.
La comparaison entre le texte brut du fragment du sonnet et son encodage nous permet de commencer à voir les avantages de la TEI en tant que langage de description de texte. Dans l’exemple précédent, il n’est pas seulement indiqué explicitement que les lignes deux à cinq sont des vers d’un poème, mais qu’elles ont un type de rime et de métrique. Une fois le poème ou tous les poèmes d’un recueil encodés, nous pouvons utiliser un programme pour réaliser des requêtes structurées, permettant, par exemple, d’identifier tous les poèmes qui possèdent une certaine métrique. Nous pouvons également utiliser (ou créer) une application pour déterminer combien de vers des sonnets de Louise Labé – s’il y en a – ont une métrique imparfaite. Ou alors, nous pouvons comparer les différentes versions (les « témoins » manuscrits et imprimés) des sonnets, pour réaliser leur édition critique.
Par ailleurs, un autre type de structuration aurait permis les études suggérées dans le paragraphe antérieur. La TEI vient faciliter cette description en offrant un cadre conceptuel et formel adapté à un grand nombre de situations textuelles. Si nous avions seulement le texte brut des sonnets, il serait techniquement impossible de profiter des outils informatiques conçus pour les éditer, transformer, visualiser, analyser ou publier.
Structure minimale d’un document TEI
Examinons maintenant la structure minimale d’un document TEI :
<?xml version="1.0" encoding="UTF-8"?>
<TEI xmlns="http://www.tei-c.org/ns/1.0">
<teiHeader>
<fileDesc>
<titleStmt>
<title>Titre</title>
</titleStmt>
<publicationStmt>
<p>Information de publication</p>
</publicationStmt>
<sourceDesc>
<p>Information sur la source</p>
</sourceDesc>
</fileDesc>
</teiHeader>
<text>
<body>
<p>Du texte...</p>
</body>
</text>
</TEI>
La première ligne est la déclaration habituelle du document XML.
La deuxième ligne contient l’élément principal ou « racine » de ce document : l’élément <TEI>. L’attribut @xmlns avec la valeur http://www.tei-c.org/ns/1.0 déclare simplement que l’élément <TEI> et tous ses descendants appartiennent, par défaut, à l’espace de nom (namespace) de la TEI. Désormais, cela ne devra plus nous préoccuper.
Ce qui nous intéresse arrive après, dans les lignes 3 et 16, qui contiennent respectivement les deux enfants immédiats de la racine :
Voyons maintenant en quoi consistent ces deux éléments.
L’élément <teiHeader>
Toutes les métadonnées du document sont encodées dans l’élément <teiHeader> : le titre, les auteurs ou les autrices, où, quand et comment il a été publié, sa source, d’où a été tirée la source, etc. Il est courant que les personnes qui commencent à encoder des textes en TEI passent outre ces informations, remplissant ces champs avec des données génériques et incomplètes. Cependant, l’information du <teiHeader> est essentielle à la tâche de l’encodeur ou de l’encodeuse, car elle sert à identifier avec précision le texte encodé.
Le <teiHeader> doit contenir au moins un élément nommé <fileDesc> (file description ou description du fichier), qui contient trois éléments enfants en même temps :
<titleStmt>(title statement ou énoncé de titre) : l’information sur le titre du document (à l’intérieur de l’élément<title>) ; optionnellement, il peut aussi inclure des données sur la ou les personnes à l’origine du document (à l’intérieur de l’élément<author>).<publicationStmt>(publication statement ou énoncé de publication) : l’information sur comment le document est publié ou est rendu disponible (autrement dit, le document TEI lui-même, non pas sa source). En ce sens, il est analogue à l’information de l’éditeur/imprimerie dans l’« imprint » ou la page de mentions légales d’un livre. Il peut être un paragraphe descriptif (à l’intérieur d’un élément générique de paragraphe<p>) ou il peut être structuré dans un ou plusieurs champs à l’intérieur des éléments suivants :<address>: l’adresse postale de la personne qui édite ou encode ;<date>: la date de publication du document ;<pubPlace>: le lieu de publication du document ;<publisher>: la personne qui édite ou encode le document ;<ref>(ou alors<ptr>) : une référence externe (URL) où le document est disponible.
<sourceDesc>(source description ou description de la source) : l’information sur la source dont on tire le texte qui est en train d’être encodé. Il peut être un paragraphe descriptif (à l’intérieur d’un élément générique de paragraphe,<p>). Il peut aussi être structuré de plusieurs façons. Par exemple, il peut avoir un élément<bibl>, qui inclut une référence bibliographique non structurée (par exemple,<bibl>Victor Hugo, "Les Misérables", Paris : Pagnerre, 1862) ; ou il peut contenir une référence structurée à l’intérieur de l’élément<biblStruct>qui contient à son tour d’autres éléments remarquables.
Supposons que nous voulons encoder la cinquième partie des Misérables de Victor Hugo, à partir de cette édition disponible librement sur Gallica. Le <teiHeader> de notre document pourrait bien être le suivant :
<teiHeader>
<fileDesc>
<titleStmt>
<title>Les Misérables</title>
<author>Victor Hugo</author>
</titleStmt>
<publicationStmt>
<p>
Encodage en TEI par Maritza Beatriz García Rodríguez en juillet 2025.
</p>
</publicationStmt>
<sourceDesc>
<p>
Texte issu de :
Victor Hugo, "Les Misérables". Cinquième partie : "Jean Valjean" I, Paris : Pagnerre, 1862.
Disponible ici : https://gallica.bnf.fr/ark:/12148/bpt6k411301m/f4.item
</p>
</sourceDesc>
</fileDesc>
</teiHeader>
Il s’agit des informations minimales nécessaires à l’identification du document encodé. Elles indiquent le titre et l’auteur du texte, la personne responsable de l’encodage et la source d’où provient le texte.
Cependant, il est possible – et parfois souhaitable – de spécifier plus en détail les métadonnées du document. Par exemple, considérons cette autre version du <teiHeader> pour le même texte :
<teiHeader>
<fileDesc>
<titleStmt>
<title>Les Misérables</title>
<author>Victor Hugo</author>
</titleStmt>
<publicationStmt>
<publisher>Maritza Beatriz García Rodríguez</publisher>
<pubPlace>Lyon, France</pubPlace>
<date>2025</date>
<availability>
<p>Cette œuvre est en accès libre sous la licence Creative Commons Attribution 4.0 International.</p>
</availability>
<ref target="https://github.com/ElvisKarlsson"/>
</publicationStmt>
<sourceDesc>
<biblStruct>
<monogr>
<author>Victor Hugo</author>
<title>Les Misérables</title>
<edition>1</edition>
<imprint>
<publisher>Pagnerre</publisher>
<pubPlace>Paris</pubPlace>
<date>1862</date>
</imprint>
<biblScope unit="partie" n="5">Jean Valjean</biblScope>
<bibleScope unit="tome" n="1">I</biblScope>
</monogr>
<ref target="https://gallica.bnf.fr/ark:/12148/bpt6k6558010n/f9.item"/>
</biblStruct>
</sourceDesc>
</fileDesc>
</teiHeader>
Le choix sur l’exhaustivité de l’information du <teiHeader> dépend de sa disponibilité, et obéit aux objectifs de l’encodage et aux intérêts de la personne qui édite ou encode. Cependant, bien que les métadonnées contenues dans le <teiHeader> d’un document TEI n’apparaissent pas nécessairement de façon littérale dans le texte encodé, cela ne signifie pas qu’elles ne sont pas pertinentes pour le processus d’encodage, d’édition et d’éventuelle transformation. De même, dans la mesure où le <teiHeader> a été correctement et exhaustivement encodé, on pourra extraire et transformer l’information contenue dans le document.
Par exemple, s’il était important pour nous de distinguer les différentes éditions et impressions des Misérables, l’information contenue dans les <teiHeader> des différents documents transcrits serait suffisante pour pouvoir les discriminer automatiquement. En effet, on pourrait profiter des éléments <edition> et <imprint> – à cette fin, et avec l’aide de technologies comme XPath, XSLT et XQuery, nous pourrions situer, extraire et traiter toute cette information.
En définitive, plus les métadonnées des textes sont encodées de manière complète et minutieuse dans le <teiHeader> de nos documents TEI, plus nous arriverons à contrôler son identité et sa nature.
L’élément <text>
Comme nous l’avons vu ci-dessus dans la structure minimale, <text> est le deuxième enfant de <TEI>. Il contient tout le texte du document, proprement dit. Selon la documentation de la TEI, <text> peut contenir une série d’éléments dans lesquels l’objet-texte doit être structuré :

Figure 12. Des éléments possibles de <text>.
Le plus important parmi ces éléments est <body>, qui contient le corps principal du texte. Néanmoins, d’autres éléments importants enfants de <text> sont <front>, qui contient le frontmatter (les pages préliminaires) d’un texte (introduction, prologue, etc.), et <back>, qui contient le backmatter (les pages finales, des annexes, des index, etc.).
Pour sa part, l’élément <body> peut lui-même contenir beaucoup d’autres éléments :

Figure 13. Des éléments possibles de <body>.
Bien que toutes ces possibilités puissent nous accabler à première vue, nous devons nous rappeler que, d’habitude, un texte se divise naturellement en sections ou parties constitutives. Il est donc recommandable d’utiliser l’élément <div> pour chacune d’elles et d’utiliser des attributs tels que @type ou @n pour qualifier leurs différentes classes et positions dans le texte (par exemple, <div n="3" type="sous-section">...</div>).
Si notre texte est court ou simple, nous pourrions n’utiliser qu’un seul <div>. Par exemple :
<text>
<body>
<div>
<!-- tout notre texte se trouverait ici -->
</div>
</body>
</text>
Mais si notre texte est plus complexe, nous utiliserions plusieurs éléments <div> :
<text>
<body>
<div>
<!-- la première section ou division se trouverait ici -->
</div>
<div>
<!-- la deuxième section ou division se trouverait ici -->
</div>
<!-- etc. -->
</body>
</text>
En principe, la structure de notre document TEI doit être similaire à la structure de l’objet-texte, c’est-à-dire, du texte que nous voulons encoder. Ainsi, si notre objet-texte se divise en chapitres, et ceux-ci, en même temps, en paragraphes, alors nous recommandons de reproduire la même structure dans le document TEI.
Pour les chapitres et les sections, nous pouvons utiliser l’élément <div> et pour les paragraphes l’élément <p>.
Observons, par exemple, le schéma suivant :
<text>
<body>
<div type="chapitre" n="1">
<!-- ceci est le premier chapitre -->
<div type="section" n="1">
<!-- celle-ci est la première section -->
<p>
<!-- ceci est le premier paragraphe -->
</p>
<p>
<!-- ceci est le deuxième paragraphe -->
</p>
<!-- ... -->
</div>
</div>
<!-- ... -->
</body>
</text>
Bien que la TEI nous permette d’encoder exhaustivement beaucoup d’aspects et de propriétés d’un texte, nous ne souhaitons pas nécessairement tous les encoder. De plus, le processus d’encodage peut être inutilement chronophage si nous prenons le temps d’encoder des éléments dont nous n’avons pas besoin pour les transformations envisagées. Par exemple, si nous sommes en train d’encoder le texte d’une édition imprimée, il peut arriver que les divisions de ligne dans les paragraphes ne soient pas pertinentes pour notre encodage.
Dans ce cas, nous pouvons les ignorer et garder seulement les divisions de paragraphe, sans descendre au-delà de celles-ci. Peut-être ressentons-nous aussi la tentation d’encoder systématiquement toutes les dates et les noms de lieux (avec les éléments <date> et <placeName>, respectivement) qui apparaissent dans notre objet-texte, même si nous n’en profiterons pas ultérieurement. Le faire n’est pas une erreur, mais nous risquons de perdre un temps précieux.
En somme, nous pourrions ainsi formuler la « règle d’or » de l’encodage : encodons tous les éléments qui ont pour nous une signification déterminée, et seulement ceux-là, tout en prenant en compte le fait que nous pourrons éventuellement en profiter de manière concrète.
Conclusion
Dans cette première partie de la leçon, vous avez appris :
- Ce que signifie encoder un texte.
- Ce que sont les documents XML et XML-TEI.
Dans la deuxième partie (qui n’existe actuellement qu’en espagnol) vous verrez en détail deux exemples d’encodages de textes. Une autre leçon, par Gabriel Calarco et Gimena del Rio Rande, est dédiée à l’utilisation de CETEIcean.
Références recommandées
-
La documentation complète de la TEI (les TEI Guidelines) disponible sur le site du consortium. Bien qu’elle soit disponible en plusieurs langues, seule la version anglophone est complète.
-
L’ouvrage Qu’est-ce que la Text Encoding Initiative ? de Lou Burnard (trad. Marjorie Burghart, OpenEdition Press, Marseille, 2015), disponible gratuitement en ligne, est une bonne introduction à la TEI.
-
Un bon tutoriel pour XML est disponible en anglais sur : https://www.w3schools.com/xml/.
-
Le consortium de la TEI offre aussi une bonne introduction à XML en anglais.
-
La documentation officielle de XML est disponible en anglais sur le site du consortium W3C. La documentation pour toute la famille XSL (y compris XSLT) est aussi disponible en anglais.
-
La Mozilla Foundation offre aussi un bon site sur XSLT et des technologies associées en français et en anglais.
-
Le site TTHUB contient une excellente Introducción a la Text Encoding Initiative, en langue espagnole, par Susanna Allés Torrent (2019).
-
Une leçon d’introduction de Programming Historian à XML et aux transformations XSL est Transforming Data for Reuse and Re-publication with XML and XSL, de M. H. Beals (ressource en anglais).
-
Le MOOC de Marjorie Burghart et Elena Pierazzo : Digital Scholarly Editions: Manuscripts, Texts and TEI Encoding, en anglais.